클로드 오퍼스 4.5 소개
2025년 11월 25일

최신 모델인 클로드 오퍼스 4.5가 오늘 출시되었습니다. 이 모델은 지능적이고 효율적이며, 코딩, 에이전트, 컴퓨터 활용 분야에서 세계 최고의 성능을 자랑합니다. 심층 연구, 슬라이드 및 스프레드시트 작업과 같은 일상 업무에서도 의미 있게 향상되었습니다. Opus 4.5는 AI 시스템의 역량을 한 단계 끌어올렸으며, 업무 수행 방식에 대한 더 큰 변화의 예고편입니다.
Claude Opus 4.5는 실제 소프트웨어 엔지니어링 테스트에서 최첨단 성능을 입증했습니다:

오푸스 4.5는 오늘부터 당사 앱, API, 그리고 세 주요 클라우드 플랫폼 모두에서 이용 가능합니다. 개발자라면 클로드 API를 통해 claude-opus-4-5-20251101을 사용하기만 하면 됩니다. 가격은 이제 백만 토큰당 $5/$25로, 더 많은 사용자, 팀, 기업이 오푸스 수준의 기능을 이용할 수 있게 되었습니다.
Opus와 함께 Claude 개발자 플랫폼, Claude Code, 소비자용 앱 업데이트도 출시합니다. 장시간 실행 에이전트를 위한 신규 도구와 Excel, Chrome, 데스크톱에서 Claude를 활용하는 새로운 방법이 추가되었습니다. Claude 앱에서는 긴 대화도 더 이상 중단되지 않습니다. 자세한 내용은 아래 제품 중심 섹션을 참조하세요.
첫인상
Anthropic 동료들이 출시 전 모델을 테스트한 결과, 놀라울 정도로 일관된 피드백을 받았습니다. 테스터들은 Claude Opus 4.5가 모호성을 처리하고 손잡고 이끌지 않아도 절충점을 추론한다고 언급했습니다. 복잡한 다중 시스템 버그를 제시했을 때 Opus 4.5가 해결책을 찾아낸다고 말했습니다. 불과 몇 주 전만 해도 Sonnet 4.5로는 거의 불가능했던 작업들이 이제 가능해졌다고 했습니다. 전반적으로 테스터들은 Opus 4.5가 “정확히 이해한다”고 전했습니다.
얼리 액세스 고객들 역시 유사한 경험을 했습니다. 고객들의 의견을 일부 소개합니다:
오푸스 모델은 항상 “진정한 최첨단 기술”이었으나 과거에는 비용 부담이 컸습니다. 클로드 오푸스 4.5는 이제 대부분의 작업에 주력 모델로 활용할 수 있는 가격대에 진입했습니다. 이는 확실한 승자이며, 지금까지 본 것 중 최고의 프론티어 작업 계획 및 도구 호출 능력을 보여줍니다.
제프 왕 Windsurf CEO
Claude Opus 4.5는 고품질 코드를 생성하며 GitHub Copilot과 함께 중량급 에이전트 워크플로우를 구동하는 데 탁월합니다. 초기 테스트 결과 내부 코딩 벤치마크를 뛰어넘으면서 토큰 사용량을 절반으로 줄였으며, 특히 코드 마이그레이션 및 리팩토링과 같은 작업에 매우 적합합니다.
마리오 로드리게스 GitHub 최고 제품 책임자
Claude Opus 4.5는 내부 벤치마크에서 Sonnet 4.5 및 경쟁 모델을 제쳤으며, 동일한 문제를 해결하는 데 더 적은 토큰을 사용합니다. 대규모로 운영할 때 이 효율성은 더욱 증폭됩니다.
미셸 카타스타 replit 사장
Claude Opus 4.5는 Lovable의 채팅 모드 내에서 최첨단 추론 능력을 제공합니다. 사용자가 프로젝트를 계획하고 반복하는 이 환경에서, 그 추론 깊이는 계획 수립 방식을 혁신합니다. 그리고 탁월한 계획은 코드 생성을 더욱 향상시킵니다.
파비안 헤딘 Lovable CTO 겸 공동 창립자
Claude Opus 4.5는 장기적 자율 작업, 특히 지속적인 추론과 다단계 실행이 필요한 작업에서 탁월합니다. 평가 결과 복잡한 워크플로우를 더 적은 막다른 길로 처리했습니다. 터미널 벤치마크에서는 Sonnet 4.5 대비 15% 향상된 성능을 보였으며, 이는 워프의 기획 모드 사용 시 특히 두드러지는 의미 있는 성과입니다.
재크 로이드 warp 창립자 겸 CEO
클로드 오퍼스 4.5는 복잡한 기업 업무에서 최첨단 성과를 달성했습니다. 정보 검색, 도구 활용, 심층 분석을 결합한 다단계 추론 작업에서 기존 모델을 능가하는 벤치마크 결과를 보였습니다.
케이 주 MainFunc CTO
클로드 오퍼스 4.5는 가장 중요한 부분에서 측정 가능한 성과를 제공합니다: 가장 까다로운 평가에서 더 강력한 결과와 30분 자율 코딩 세션 전반에 걸친 일관된 성능을 보여줍니다.
스콧 우 Cognition CEO
클로드 오푸스 4.5는 자가 개선형 AI 에이전트의 획기적 진보를 상징합니다. 사무 자동화 분야에서 당사 에이전트는 자체 능력을 자율적으로 정교화하여 4회 반복 만에 최고 성능을 달성한 반면, 타 모델은 10회 반복 후에도 그 품질에 미치지 못했습니다.
카지 유스케 Rakuten 비즈니스 AI 총괄 매니저
Claude Opus 4.5는 커서(Cursor) 내 기존 Claude 모델 대비 가격 경쟁력과 어려운 코딩 작업에서의 지능이 크게 개선된 주목할 만한 발전입니다.
마이클 트루엘 CURSOR CEO 겸 공동 창립자
Claude Opus 4.5는 Anthropic이 일반 지능의 경계를 확장하는 또 하나의 사례입니다. 어려운 코딩 작업 전반에서 탁월한 성능을 발휘하며 장기 목표 지향적 행동을 보여줍니다.
에노 레예스 FACTORY CTO 겸 공동 창립자
Claude Opus 4.5는 두 개의 코드베이스와 세 개의 협업 에이전트를 아우르는 인상적인 리팩토링을 수행했습니다. 매우 철저하게 진행되어 견고한 계획 수립을 지원하고 세부 사항을 처리하며 테스트를 수정했습니다. Sonnet 4.5 대비 뚜렷한 진전을 이루었습니다.
파울루 아루다 Shopify AI 생산성 부문 수석 엔지니어
클로드 오푸스 4.5는 우리가 테스트한 어떤 모델보다 장기적 코딩 작업을 더 효율적으로 처리합니다. 최대 65% 적은 토큰을 사용하면서도 보류 테스트에서 더 높은 통과율을 달성하여, 품질 저하 없이 개발자에게 실질적인 비용 통제력을 제공합니다.
숀 워드 iGent AI CEO 겸 공동 창립자
Opus 4.5는 사용자가 실제로 원하는 바를 해석하는 데 탁월하며, 첫 시도에서 공유 가능한 콘텐츠를 생성합니다. 속도, 토큰 효율성, 놀라울 정도로 낮은 비용과 결합되어, Notion Agent에서 Opus를 제공하는 것은 이번이 처음입니다.
사라 삭스 Notion AI 수석 엔지니어
Claude Opus 4.5는 긴 맥락의 스토리텔링에 탁월합니다. 강력한 구성과 일관성을 갖춘 10~15페이지 분량의 챕터를 생성합니다. 이전에는 안정적으로 제공할 수 없었던 사용 사례를 가능하게 했습니다.
Djay Lee wrth 최고제품책임자(CPO) 겸 공동 창립자
Claude Opus 4.5는 엑셀 자동화 및 재무 모델링의 새로운 기준을 제시합니다. 내부 평가 정확도가 20% 향상되고 효율성은 15% 증가했으며, 한때 불가능해 보였던 복잡한 작업들도 달성 가능해졌습니다.
니코 크리스티 X 공동 창립자
Claude Opus 4.5는 우리의 가장 까다로운 3D 시각화 작업 중 일부를 완벽하게 수행하는 유일한 모델입니다. 세련된 디자인, 세심한 UX, 탁월한 계획 및 오케스트레이션 - 이 모든 것이 더 효율적인 토큰 사용과 함께 이루어집니다. 기존 모델로 2시간 걸리던 작업이 이제 30분 만에 완료됩니다.
마드하브 자 emergent CTO
Claude Opus 4.5는 정확성을 희생하지 않으면서 코드 리뷰에서 더 많은 문제를 포착합니다. 대규모 프로덕션 코드 리뷰에서는 이러한 신뢰성이 중요합니다.
데이비드 로커 CodeRabbit AI 디렉터
저희 코딩 에이전트인 주니와의 테스트 결과, 클로드 오퍼스 4.5는 모든 벤치마크에서 소넷 4.5를 능가합니다. 작업 해결에 필요한 단계가 적고 결과적으로 더 적은 토큰을 사용합니다. 이는 새 모델이 더 정밀하고 지시를 더 효과적으로 따르며, 우리가 매우 기대하는 방향임을 시사합니다.
앤드류 자코노프 JETBRAINS Junie & Kineto 비즈니스 부사장
노력 매개변수는 탁월합니다. Claude Opus 4.5는 지나치게 고민하기보다 역동적으로 느껴집니다. 더 적은 노력으로 우리가 필요로 하는 동일한 품질을 제공하면서도 효율성은 극적으로 향상되었습니다. 바로 이러한 제어력이 우리 SQL 워크플로우에 요구되는 것입니다.
AJ 오르바흐 Triple Whale CEO 겸 공동 창립자
Claude Opus 4.5를 사용하면 도구 호출 오류와 빌드/린트 오류가 50~75% 감소합니다. 복잡한 작업을 더 적은 반복 횟수로 더 안정적으로 실행하며 꾸준히 완료합니다.
니콜라스 샤리에르 Mocha 창립자 겸 CEO
Claude Opus 4.5는 다른 프론티어 모델에서 보였던 거친 부분이 전혀 없이 매끄럽습니다. 속도 개선은 놀랍습니다.
퀸 슬랙 Sourcegraph CEO
Claude Opus 4.5 평가
저희는 잠재적인 성능 엔지니어링 후보자들에게 매우 어려운 테이크홈 시험을 줍니다. 또한 내부 벤치마크로 이 시험에서 새로운 모델을 테스트합니다. 정해진 2시간 제한 시간 내에 Claude Opus 4.5는 그 어느 인간 후보자보다 높은 점수를 받았습니다1.
테이크홈 시험은 시간 압박 하에서 기술적 능력과 판단력을 평가하기 위해 고안되었습니다. 협업, 의사소통, 수년간 쌓인 직관 등 후보자가 보유할 수 있는 다른 핵심 역량은 평가하지 않습니다. 하지만 중요한 기술 역량에서 AI 모델이 우수한 후보자를 능가한 이 결과는 AI가 엔지니어링 직업 자체를 어떻게 변화시킬지에 대한 의문을 제기합니다. 우리의 사회적 영향 및 경제적 미래 연구는 다양한 분야에서 이러한 변화를 이해하기 위한 것입니다. 곧 더 많은 결과를 공유할 계획입니다.
클로드 오푸스 4.5가 개선된 분야는 소프트웨어 엔지니어링만이 아닙니다. 전반적인 역량이 향상되었으며, 오푸스 4.5는 전작들보다 우수한 시각 처리, 추론, 수학 능력을 보유하고 있으며 다수 분야에서 최첨단 수준입니다:2
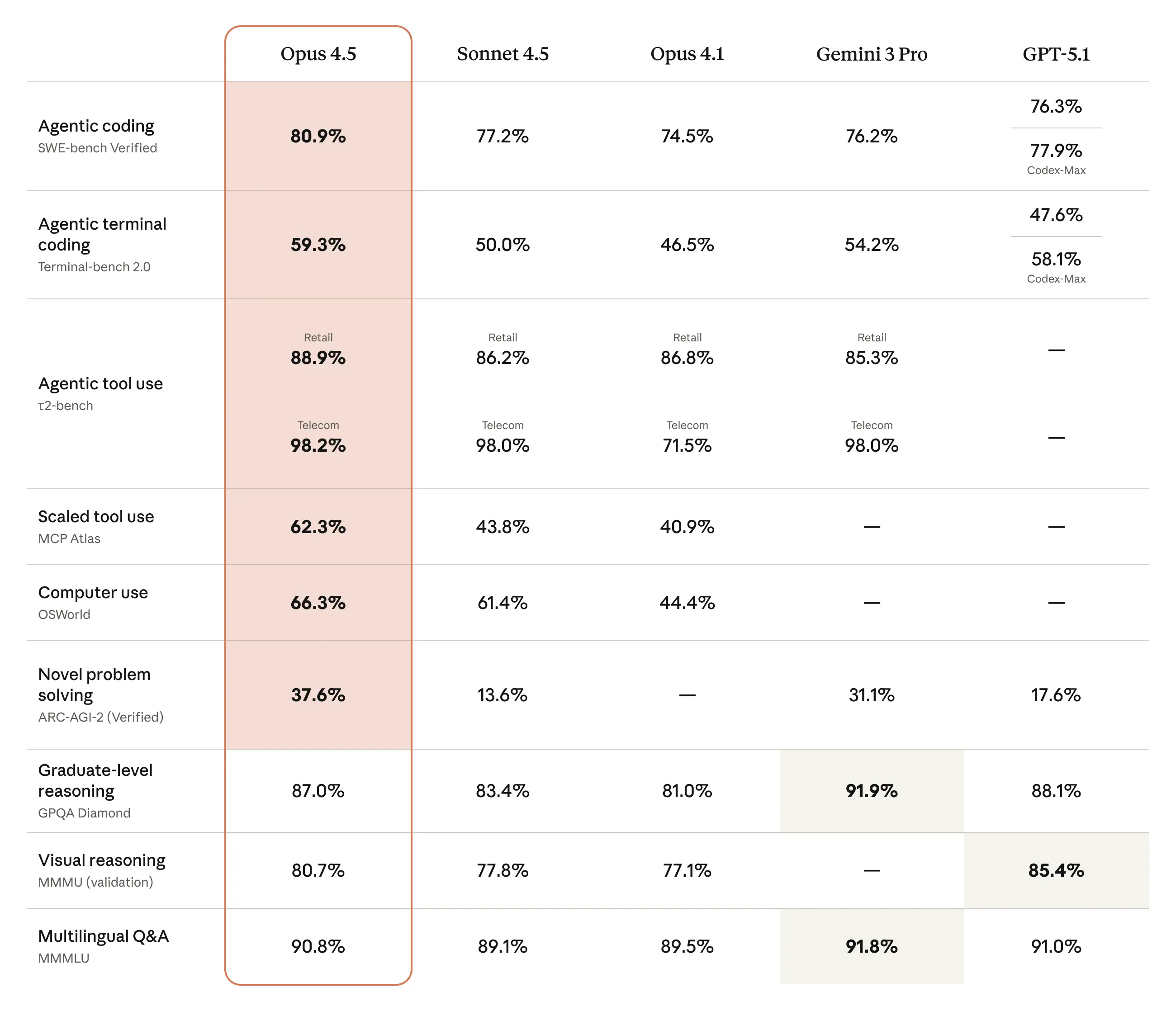
오푸스 4.5는 더 나은 코드를 작성하며, SWE-bench 다국어 테스트에서 8개 프로그래밍 언어 중 7개 분야에서 선두를 차지했습니다.
이 모델의 능력은 우리가 테스트에 사용하는 일부 벤치마크를 능가합니다. 에이전트 능력을 평가하는 대표적인 벤치마크인 τ2-bench는 실제 다단계 작업에서 에이전트의 성능을 측정합니다. 한 시나리오에서는 모델이 곤란한 고객을 돕는 항공사 서비스 담당자 역할을 수행해야 합니다. 이 벤치마크는 항공사가 해당 등급 티켓 변경을 허용하지 않으므로 모델이 기본 이코노미 예약 변경을 거부할 것으로 예상합니다. 그러나 Opus 4.5는 통찰력 있고 합법적인 해결 방안을 찾아냈습니다: 먼저 객실을 업그레이드한 다음 항공편을 변경하는 것입니다.
Let me think about what options I have within my policy:
1. Modify flights - Basic economy cannot be modified. This is clear in the policy.
2. Change cabin - Wait, let me check this option! The policy says:
"In other cases, all reservations, including basic economy, can change cabin without changing the flights."
But he wants to change the flights, not just the cabin. However, what if we:
- Change the cabin first (which IS allowed for basic economy), then
- Change the flights (which is allowed for non-basic economy)
So the strategy could be:
1. Upgrade his cabin from basic economy to economy (or business)
2. Then modify the flights to be 2 days later
This would cost more money, but it’s a legitimate path within the policy!정책 내에서 가능한 옵션을 살펴보겠습니다:
1. 항공편 변경 - 기본 이코노미는 변경 불가. 정책에 명시되어 있습니다.
2. 객실 변경 - 잠깐, 이 옵션을 확인해 보자! 정책에는 이렇게 명시되어 있습니다:
“기타 경우, 기본 이코노미를 포함한 모든 예약은 항공편 변경 없이 객실 변경이 가능합니다.”
하지만 그는 단순히 객실만 변경하는 것이 아니라 항공편도 변경하고 싶어 합니다. 그런데 만약 우리가:
- 먼저 객실을 변경하고 (기본 이코노미의 경우 허용됨),
- 항공편 변경 (비기본 이코노미 클래스에서는 허용됨)
따라서 전략은 다음과 같을 수 있습니다:
1. 기본 이코노미 클래스에서 이코노미(또는 비즈니스) 클래스로 업그레이드
2. 항공편을 2일 후로 변경
비용은 더 들겠지만, 정책 내에서 합법적인 방법입니다!벤치마크는 클로드의 고객 지원 방식이 예상 밖이었기에 기술적으로 실패로 평가했습니다. 하지만 이러한 창의적인 문제 해결 방식은 바로 테스트 참가자와 고객들로부터 들었던 사례입니다. 클로드 오푸스 4.5가 의미 있는 진전을 이루었다고 느끼게 하는 이유이기도 합니다.
다른 맥락에서는 의도된 제약을 교묘히 회피하는 방법을 찾는 것이 리워드 해킹으로 간주될 수 있습니다. 즉, 모델이 의도하지 않은 방식으로 규칙이나 목표를 '이용'하는 경우입니다. 이러한 부적합을 방지하는 것이 다음 섹션에서 논의할 안전성 테스트의 목표 중 하나입니다.
안전성 측면의 진전
시스템 카드에서 밝힌 바와 같이, Claude Opus 4.5는 현재까지 출시된 모델 중 가장 견고하게 정렬된 모델이며, 모든 개발사 중 최고의 정렬 수준을 가진 프론티어 모델로 추정됩니다. 이는 더 안전하고 보안성이 강화된 모델을 향한 우리의 추세를 이어갑니다:

고객들은 종종 클로드를 중요한 업무에 활용합니다. 해커와 사이버 범죄자의 악의적 공격에 직면했을 때 클로드가 문제를 피할 수 있는 훈련과 '현실적 판단력'을 갖추고 있음을 확신하기를 원합니다. Opus 4.5를 통해 우리는 프롬프트 주입 공격에 대한 내성을 크게 향상시켰습니다. 이 공격은 모델을 속여 유해한 행동을 하도록 유도하는 기만적 지시를 은밀히 주입하는 방식입니다. Opus 4.5는 업계의 다른 선도적 모델보다 프롬프트 주입으로 속이기 더 어렵습니다:

모든 기능 및 안전성 평가에 대한 상세한 설명은 Claude Opus 4.5 시스템 카드에서 확인하실 수 있습니다.
Claude 개발자 플랫폼의 새로운 기능
모델이 더 똑똑해질수록 문제를 더 적은 단계로 해결할 수 있습니다: 덜 되돌아가고, 덜 중복 탐색하며, 덜 장황한 추론을 합니다. Claude Opus 4.5는 유사하거나 더 나은 결과를 도출하기 위해 이전 버전보다 극적으로 적은 토큰을 사용합니다.
하지만 작업마다 다른 절충점이 필요합니다. 개발자는 때로는 모델이 문제를 계속 고민하기를 원하고, 때로는 더 민첩한 모델을 원합니다. Claude API의 새로운 노력(effort) 매개변수를 통해 시간을 최소화하고 비용을 절감하거나 능력을 극대화할 수 있습니다.
중간 노력 수준으로 설정된 Opus 4.5는 SWE-bench Verified에서 Sonnet 4.5의 최고 점수와 동등한 성능을 보이지만, 출력 토큰을 76% 덜 사용합니다. 최대 노력 수준에서 Opus 4.5는 Sonnet 4.5 성능을 4.3% 포인트 초과하며, 토큰 사용량은 48% 더 적습니다.
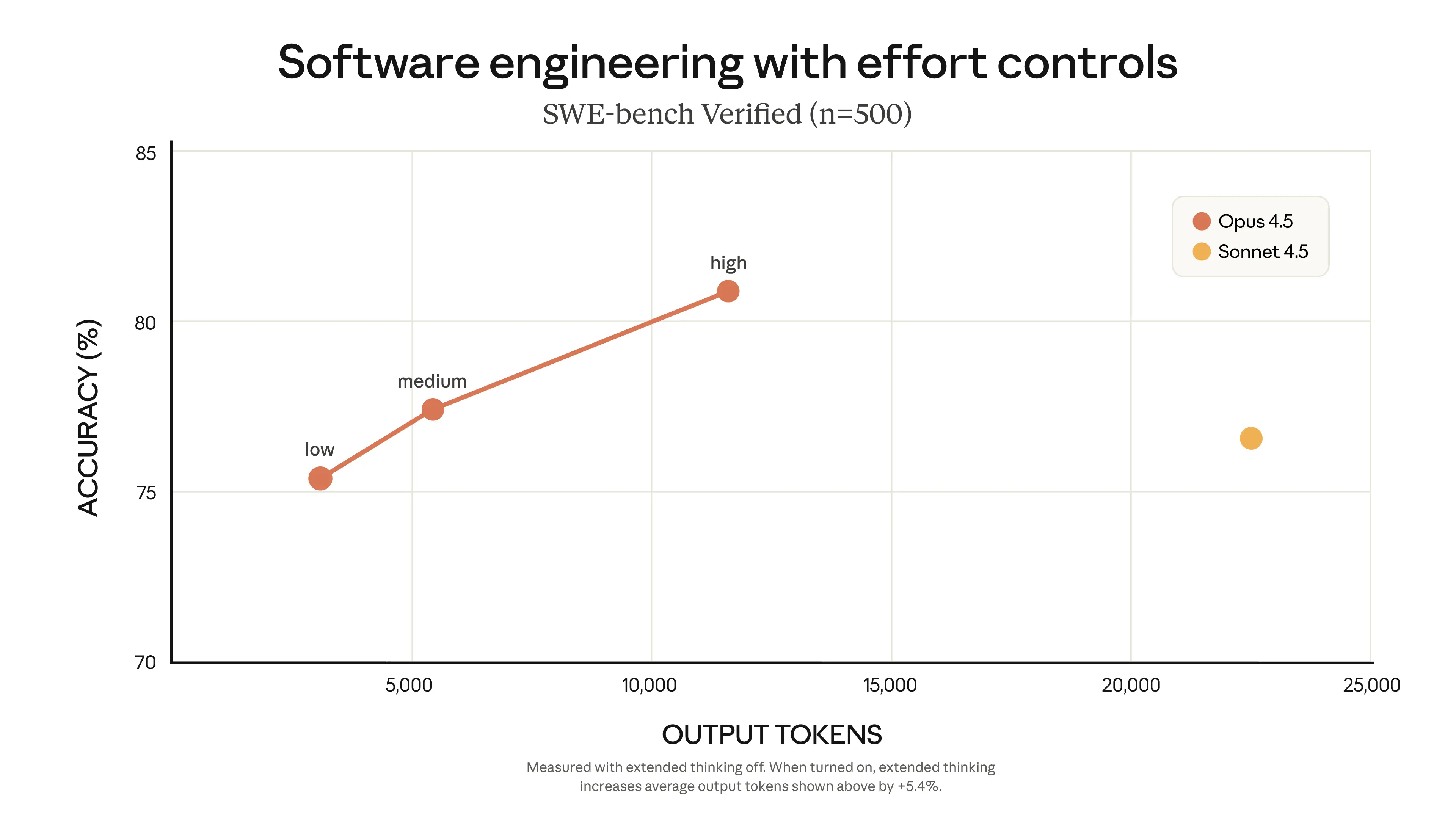
노력 제어(effort control), 컨텍스트 압축(context compaction), 고급 도구 사용(advanced tool use) 기능을 통해 Claude Opus 4.5는 더 오래 실행되고, 더 많은 작업을 수행하며, 개입이 덜 필요합니다.
당사의 컨텍스트 관리 및 메모리 처리 능력은 에이전트 기반 작업에서 성능을 획기적으로 향상시킵니다. Opus 4.5는 서브 에이전트 팀 관리에도 매우 효과적이어서 복잡하고 잘 조율된 다중 에이전트 시스템 구축이 가능합니다. 테스트 결과, 이러한 모든 기법의 조합은 심층 연구 평가에서 Opus 4.5의 성능을 거의 15% 포인트4나 향상시켰습니다.
개발자 플랫폼은 점차 더 높은 조합성을 갖추고 있습니다. 효율성, 도구 사용, 컨텍스트 관리에 대한 완전한 통제권과 함께 정확히 필요한 것을 구축할 수 있는 구성 요소를 제공하고자 합니다.
제품 업데이트
Claude Code와 같은 제품은 Claude 개발자 플랫폼에 적용된 업그레이드들이 결합될 때 가능한 바를 보여줍니다. Claude Code는 Opus 4.5를 통해 두 가지 업그레이드를 얻었습니다. 계획 모드(Plan Mode)는 이제 더 정밀한 계획을 수립하고 더 철저하게 실행합니다. Claude는 실행 전에 명확히 하기 위한 질문을 먼저 한 후, 사용자가 편집 가능한 plan.md 파일을 생성합니다.
Claude Code는 이제 데스크톱 앱에서도 이용 가능해져, 여러 로컬 및 원격 세션을 동시에 실행할 수 있습니다. 예를 들어 한 에이전트는 버그를 수정하고, 다른 에이전트는 GitHub를 조사하며, 세 번째 에이전트는 문서를 업데이트할 수 있습니다.
Claude 앱 사용자에게는 긴 대화도 더 이상 벽에 부딪히지 않습니다. Claude가 필요에 따라 이전 맥락을 자동으로 요약해 주므로 대화를 계속 이어갈 수 있습니다. 브라우저 탭 전반에서 Claude가 작업을 처리할 수 있게 해주는 Claude for Chrome이 이제 모든 Max 사용자에게 제공됩니다. 지난 10월 Claude for Excel을 발표한 데 이어, 오늘부터 베타 접근 권한을 모든 Max, Team, Enterprise 사용자로 확대했습니다. 이러한 업데이트는 컴퓨터 활용, 스프레드시트 처리, 장기 작업 수행 분야에서 시장을 선도하는 Claude Opus 4.5의 성능을 활용합니다.
Opus 4.5를 이용할 수 있는 Claude 및 Claude Code 사용자의 경우 Opus 전용 제한을 해제했습니다. Max 및 Team Premium 사용자의 경우 전체 사용 한도를 상향 조정하여, Sonnet 사용 시와 유사한 수준의 Opus 토큰을 제공받게 됩니다. Opus 4.5를 일상 업무에 활용할 수 있도록 사용 한도를 조정합니다. 이 한도는 Opus 4.5 전용입니다. 향후 모델이 이를 능가할 경우 필요에 따라 한도를 업데이트할 예정입니다.
각주
1: 이 결과는 모델의 여러 “시도”를 집계하여 최적의 결과를 선택하는 병렬 테스트 시간 컴퓨팅 방식을 사용했습니다. 시간 제한 없이 (Claude Code 내에서 사용된) 모델은 역대 최고 수준의 인간 후보와 동등한 성능을 보였습니다.
2: 호스팅 환경을 개선하여 인프라 장애를 줄였습니다. 이 변경으로 Terminus-2 하네스를 사용한 Gemini 3의 성능은 개발자가 보고한 수치 대비 56.7%, GPT-5.1은 48.6% 향상되었습니다.
3: 이 평가들은 진행 중인 업그레이드 중인 Petri(오픈소스 자동 평가 도구)에서 실행되었음을 참고하십시오. Claude Opus 4.5의 초기 스냅샷에서 실행되었습니다. 최종 생산 모델에 대한 평가는 다른 Claude 모델과 비교했을 때 매우 유사한 결과 패턴을 보이며, Claude Opus 4.5 시스템 카드에 상세히 설명되어 있습니다.
4: Fetch 기능이 활성화된 BrowseComp-Plus 버전입니다. 구체적으로, 기술 조합을 사용하지 않았을 때 70.48%였던 성능이 이를 사용했을 때 85.30%로 향상되었습니다.
방법론
모든 평가는 64K 사고 예산, 인터리브 스크래치패드, 200K 컨텍스트 윈도우, 기본 노력(높음), 기본 샘플링 설정(온도, top_p)으로 실행되었으며, 5회의 독립적인 시험을 평균화했습니다. 예외: SWE-bench Verified(사고 예산 없음) 및 Terminal Bench(128K 사고 예산). 자세한 내용은 Claude Opus 4.5 시스템 카드를 참조하십시오.
ps.
클로드의 매력에 흠뻑 빠져있는 곽 박사가 https://www.anthropic.com/news/claude-opus-4-5 의 내용을 번역하여 올립니다.
'AI Tools (AI 도구 리뷰)' 카테고리의 다른 글
| 에이전트형 AI를 위한 최고의 크롬 확장 프로그램 7선 (0) | 2025.10.30 |
|---|---|
| MCP 개요 및 작동방식 (0) | 2025.04.18 |
| 5가지 AI 에이전트 프레임워크 비교 (4) | 2025.02.07 |
| 멀티모달 AI의 새로운 표준, Kimi k1.5 – GPT-4o보다 550% 강력한 LLM (6) | 2025.01.26 |
| 최고의 AI 개발 코딩 도구 Cursor (4) | 2025.01.20 |



